Recently a project I’ve been working on had the following requirements for a file-set containing roughly a million files varying in individual size from one byte to over a gigabyte; and the file-set size in total being sized between 500gb and one terabyte
- Store this file-set on Amazon S3
- Make this file-set accessible to applications via the filesystem; i.e. access should look no different then any other directory structure locally on the Linux filesystem
- Changes on nodeA in regionA’s data-center should be available/reflected on nodeN in regionN’s data-center
- The available window to import this large file-set into S3 would be under 36 hours (due to the upgrade window for the calling application)
- The S3 bucket will need to be backed up at a minimum every 24 hours (to another bucket in S3)
- The application that will use all of the above generally treats the files as immutable and they are only progressively added and not modified.
If you are having to deal w/ a similar problem perhaps this post will help you out. Let go through each item.
Make this file-set accessible to applications via the filesystem; i.e. access should look no different then any other directory structure locally on the Linux filesystem. Changes on node-A in region-A’s data-center should be available/reflected on node-N in region-N’s data-center.
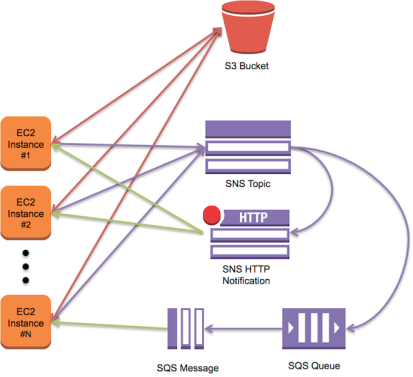
So here you are going to need an abstraction that can present the S3 bucket as a local directory structure; conceptually similar to an NFS mount. Any changes made to the directory structure should be reflected on all other nodes that mount the same set of files in S3. Now there are several different kinds of S3 file-system abstractions and they generally fall into one of three categories (block based, 1 to 1, and native), the type has big implications for if the filesystem can be distributed or not. This webpage (albeit outdated) gives a good overview that explains the different types. After researching a few of these we settled on attempting to use YAS3FS (yet another, S3 filesystem). YAS3FS, written in Python, presents an S3 bucket via a local FUSE mount; what YAS3fs adds above other S3 filesystems is that it can be “aware” of events that occur on other YA3FS nodes who mount the same bucket, and can be notified of changes via SNS/SQS messages. YAS3FS keeps a local cache on disk, so that it gives the benefits (up to a point) of local access and can act like a CDN for the files on S3. Note that FUSE based filesystems are slow and limited to a block size (IF the caller will utilize it) of 131072. YAS3FS itself works pretty good, however we are still in evaluation process as we work through many issues that are creeping up in our beta-environment, the big ones being unicode support and several concurrency issues that keep coming up. Hopefully these will be solvable in the existing code’s architecture…
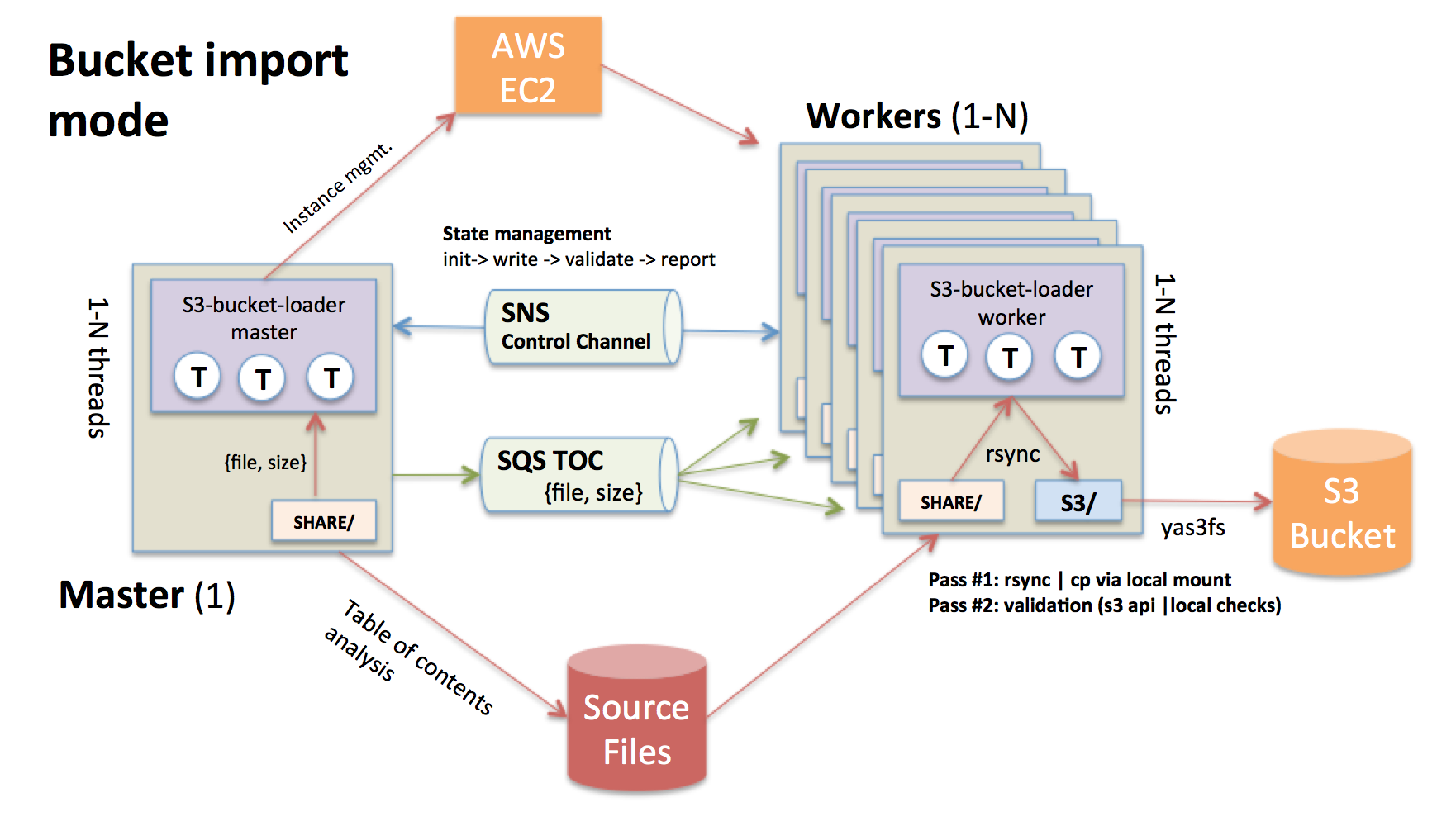
The available window to import this large file-set into S3 would be under 36 hours
Ok no problem, lets just use s3cmd. Well… tried that and it failed miserably. After several crashes and failed attempts we gave up. S3cmd is single-threaded and extremely slow to do anything against a large file-set, much less load it completely into S3. I also looked at other tools, (like s4cmd which is multi-threaded), but again, even these other “multi-threaded” tools eventually bogged down and/or became non-responsive against this large file-set.
Next we tried mounting the S3 bucket via YAS3fs and executing rsync’s from the source files to the target S3 mount…. again this “worked” without any crashing, but was single threaded and took forever. We also tried running several rsyncs in parallel, but managing this; and verifying the result, that all files were actually in S3 correctly w/ the correct meta-data, was a challenge. The particular challenge being that YAS3FS returns to rsync/cp immediately after the file is written to the local YAS3FS cache, and then proceeds to push to S3 asynchronously in the background (which makes it more difficult to check for failures).
Give the above issues, it was time to get crazy with this, so I came up with s3-bucket-loader. You can read all about how it works here, but the short of it is that s3-bucket-loader uses massive parallelism via orchestrating many ec2 worker nodes to load (and validate!) millions of files into an S3 bucket (via an s3 filesystem abstraction) much quicker than other tools. Rather than sitting around for days waiting for the copy process to complete with other tools, s3-bucket-loader can do it in a matter of hours (and validate the results). Please check it out for more details, as the github project explains it in more details.
The S3 bucket will need to be backed up at a minimum every 24 hours (to another bucket in S3)
Again, this presents another challenge; at least with copying from bucket to bucket you don’t actually have to move the files around yourself (bytes), and can rely on s3’s key-copy functionality. So again here we looked at s3cmd and s4cmd to do the job, and again they were slow, crashed, or bogged down due to the large file-set. I don’t know how these tools are managing their internal work queue, but it seems to be so large they just crash or slow down to the point where they become in-efficient. At this point you have two options for very fast bucket copying
- s3-bucket-loader: I ended up adding key-copy support to the program and it distributes the key-copy operations across ec2 worker nodes. It copies the entire fileset in under an hour, and under 20 minutes with more ec2 nodes.
- s3s3mirror: After coding #1 above, I came across s3s3mirror. This program is a multi-threaded, well coded power-house of a program that just “worked” the first time I used it. After contributing SSL, aws-encryption and storage-class support for it, doing a full bucket copy of over 600gb and ~800k s3 objects took only 45 minutes! (running w/ 100 threads). It has good status logging/output and I highly recommend it
Overall for the “copying” bucket to bucket requirement, I really like s33mirror, nice tool.
