Ever wondered how Liferay's internal clustering works? I had to dig into it in context of my other article on globally load balancing Liferay across separate data-centers. This blog post merely serves as a place for my research notes and might be helpful for someone else who is trying to follow what is going on … Continue reading Liferay clustering internals
Tag: liferay
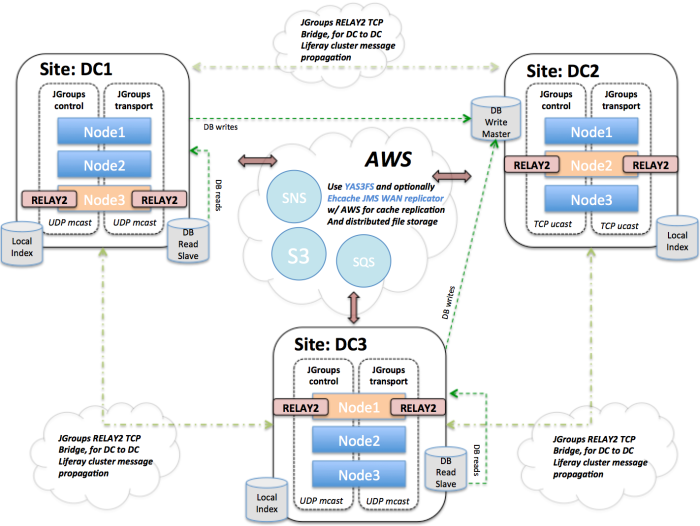
Clustering Liferay globally across data centers (GSLB) with JGroups and RELAY2
Recently I've have been looking into options to solve the problem of GSLB'ing (global server load balancing) a Liferay Portal instance. This article is a work in progress... and a long one. Jan Eerdekens states it correctly in his article, "Configuring a Liferay cluster is part experience and part black magic" .... however doing it … Continue reading Clustering Liferay globally across data centers (GSLB) with JGroups and RELAY2
Book Review: Liferay Portal 5.2 Systems Development
This is a book review of Liferay Portal 5.2 Systems Development by Jonas X. Yuan. Having no previous experience with this platform, I bought this book to try to get an overview of Liferay. The book starts out by giving an overview of Liferay and an overview of JSR-286. The bulk of the book (90%) … Continue reading Book Review: Liferay Portal 5.2 Systems Development
