This will be a quick post but could not find much on this error, so figured I'd post it for others. {"service":"AWSGlue","statusCode":400,"errorCode":"EntityNotFoundException","requestId":"xxxxx","errorMessage":"Continuation for job JobBookmark for accountId=xxxxx, jobName=myjob, runId=jr_xxxxx does not exist. not found","type":"AwsServiceError"} Was recently working on a PySpark job in AWS Glue and was attempting to use the Job Bookmarks feature which lets … Continue reading AWS Glue: Continuation for job JobBookmark does not exist
Tag: cloud computing

Immutable health check management
If you've ever had to monitor an application, endpoint or website, you've likely come across literally hundreds of monitoring services that can execute simple HTTP based checks from N global endpoints then notify an operator when certain thresholds are met. One of the more widely know services that can do this is Pingdom. On a … Continue reading Immutable health check management

Simplified orphan token creation for Hashicorp Vault
If you have a need to store secrets in a secure manner there are numerous options out there; one of the more popular and cloud agnostic ones out there is Hashicorp Vault. If you've used Vault you are likely familiar with its concept of tokens, but you may or may not be familiar with the … Continue reading Simplified orphan token creation for Hashicorp Vault
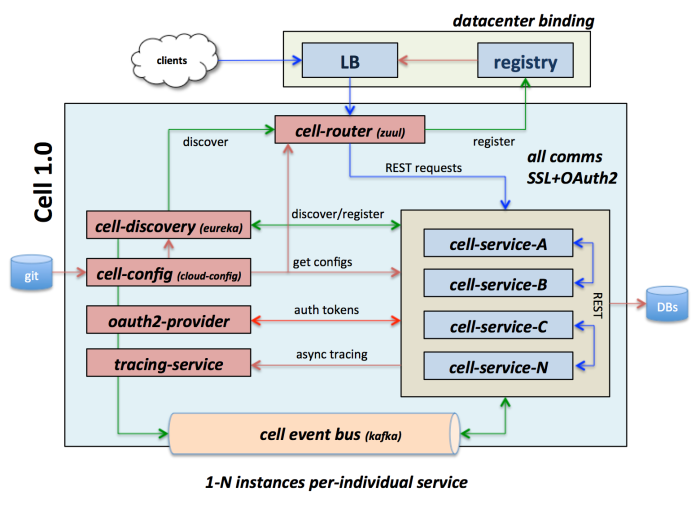
Microservices with Spring Cloud & Docker
Recent use-case with microservices using spring cloud and docker

Docker container IP and port discovery with Consul and Registrator
Do you use Docker? Does your containerized app have the need to discover both its own IP and one or more mapped ports? How can another container access my exposed ports and how can I do the same of my peers? As it stands today, simple self discovery of your container's accessible IP and one … Continue reading Docker container IP and port discovery with Consul and Registrator

Hazelcast discovery with Etcd
I've used Hazelcast for years and have generally relied upon the availability of multicast for Hazelcast cluster discovery and formation (within a single data-center). Recently was faced with two things, expand the footprint into a non-multicast enabled data-center and secondly pre-prep the service for containerization where nodes will come and go as scaling policies dictate … Continue reading Hazelcast discovery with Etcd
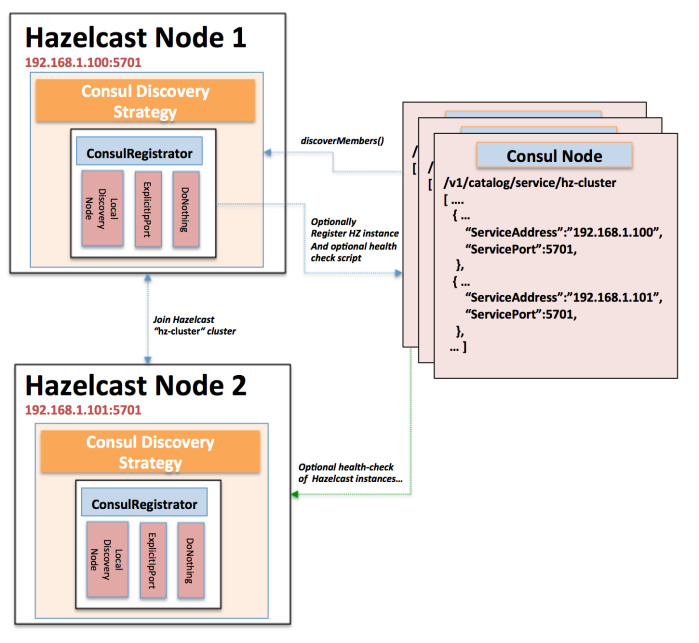
Hazelcast discovery with Consul
I've used Hazelcast for years and have generally relied upon the availability of multicast for Hazelcast cluster discovery and formation (within a single data-center). Recently was faced with two things, expand the footprint into a non-multicast enabled data-center and secondly pre-prep the service for containerization where nodes will come and go as scaling policies dictate … Continue reading Hazelcast discovery with Consul
Configuring PowerShell for Azure AD and o365 Exchange management
Ahhh, love it! So you need to configure a Windows box to be able to utilize DOS, sorry PowerShell, to remotely manage your Azure AD / o365 / Exchange online services via "cmdlets". You do some searching online and come across a ton of seemingly loosely connected Technet articles, forum questions etc. Well I hope … Continue reading Configuring PowerShell for Azure AD and o365 Exchange management
Review: Cloud Application Architectures
This is a review of the book "Cloud Application Architectures" by George Reese At about 200 pages, this book packs a lot of solid recommendations on deploying and managing an application within the cloud. The book has an admitted AWS slant, however the author covers two other providers, GoGrid and Rackspace in the appendix. That … Continue reading Review: Cloud Application Architectures
Review: Programming Amazon Web Services
Review of the book "Programming Amazon Web Services" by James Murty So I bought this book out of curiosity and the desire to start poking around with EC2. So I sat down over a weekend and plowed through most of this thing with my laptop and brand new AWS account. This is a good book, … Continue reading Review: Programming Amazon Web Services
