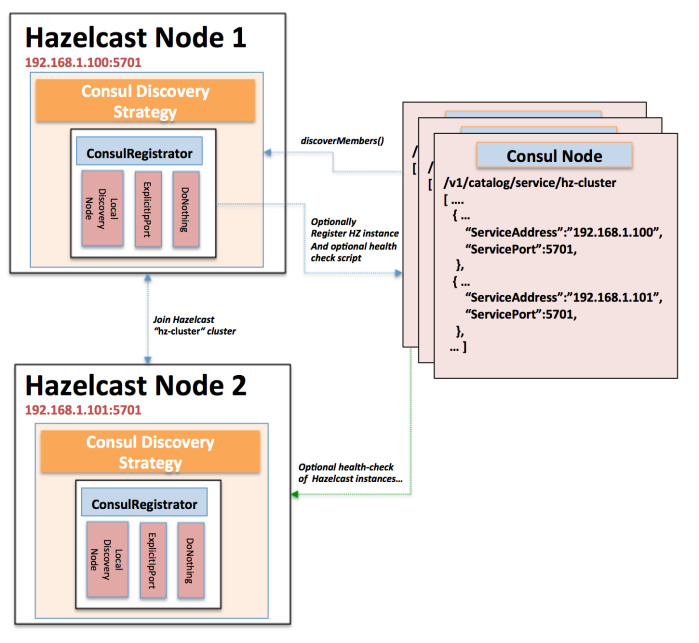
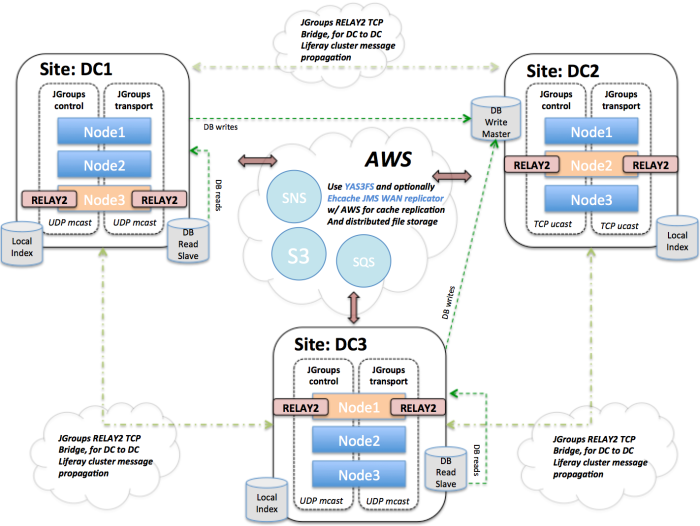
Note, this is the final part of a two part series about this project; article #1 is here. Continuing on from where we last left off, now that we had a functioning collection engine producing full graphs of crawled data all the way down to interrogable dataset_items, it was now time to get down to … Continue reading Architecture for non-deterministic mass data collection: part 2: dynamic data lake schemas